Hipotezės:
import pandas as pd
import numpy as np
from nltk.corpus import stopwords
import nltk
nltk.download('stopwords')
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
[nltk_data] Downloading package stopwords to [nltk_data] C:\Users\gedvile.ribinskaite\AppData\Roaming\nltk_data [nltk_data] ... [nltk_data] Package stopwords is already up-to-date!
movies = pd.read_csv('C:\\...\\movies_cleaned.csv', low_memory = False)# If low_memory=False,
# then whole columns will be read in first, and then the proper types determined. For example, the column will be kept as
# objects (strings) as needed to preserve information.
movies.head(3)
| id | adult | collection_id | belongs_to_collection | budget | genre_1 | genre_2 | genre_3 | genre_4 | original_title | ... | release_date | revenue | runtime | spoken_languages | status | tagline | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 862 | FALSE | 10194.0 | Toy Story Collection | 30000000 | Animation | Comedy | Family | NaN | Toy Story | ... | 10/30/1995 | 373554033.0 | 81.0 | en | Released | NaN | Toy Story | False | 7.7 | 5415.0 |
| 1 | 8844 | FALSE | NaN | NaN | 65000000 | Adventure | Fantasy | Family | NaN | Jumanji | ... | 12/15/1995 | 262797249.0 | 104.0 | en, fr | Released | Roll the dice and unleash the excitement! | Jumanji | False | 6.9 | 2413.0 |
| 2 | 15602 | FALSE | 119050.0 | Grumpy Old Men Collection | 0 | Romance | Comedy | NaN | NaN | Grumpier Old Men | ... | 12/22/1995 | 0.0 | 101.0 | en | Released | Still Yelling. Still Fighting. Still Ready for... | Grumpier Old Men | False | 6.5 | 92.0 |
3 rows × 27 columns
movies.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 45466 entries, 0 to 45465 Data columns (total 27 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 45466 non-null object 1 adult 45466 non-null object 2 collection_id 4494 non-null float64 3 belongs_to_collection 4491 non-null object 4 budget 45466 non-null object 5 genre_1 43021 non-null object 6 genre_2 28462 non-null object 7 genre_3 13982 non-null object 8 genre_4 4397 non-null object 9 original_title 45466 non-null object 10 overview 44512 non-null object 11 popularity 45461 non-null object 12 poster_path 45080 non-null object 13 production_companies_1 45463 non-null object 14 production_companies_2 17130 non-null object 15 production_countries_1 39178 non-null object 16 production_countries_2 7027 non-null object 17 release_date 45379 non-null object 18 revenue 45460 non-null float64 19 runtime 45203 non-null float64 20 spoken_languages 45459 non-null object 21 status 45379 non-null object 22 tagline 20412 non-null object 23 title 45460 non-null object 24 video 45460 non-null object 25 vote_average 45460 non-null float64 26 vote_count 45460 non-null float64 dtypes: float64(5), object(22) memory usage: 9.4+ MB
movies['adult'].value_counts()
FALSE 45454 TRUE 9 - Written by Ørnås 1 Avalanche Sharks tells the story of a bikini contest that turns into a horrifying affair when it is hit by a shark avalanche. 1 Rune Balot goes to a casino connected to the October corporation to try to wrap up her case once and for all. 1 Name: adult, dtype: int64
Matome, jog beveik visi filmai neturi amžiaus ribojimų, todėl šis rodiklis analizėje neduos jokios naudos ir jį galime pašalinti.
movies[['title', 'original_title']]
| title | original_title | |
|---|---|---|
| 0 | Toy Story | Toy Story |
| 1 | Jumanji | Jumanji |
| 2 | Grumpier Old Men | Grumpier Old Men |
| 3 | Waiting to Exhale | Waiting to Exhale |
| 4 | Father of the Bride Part II | Father of the Bride Part II |
| ... | ... | ... |
| 45461 | Subdue | رگ خواب |
| 45462 | Century of Birthing | Siglo ng Pagluluwal |
| 45463 | Betrayal | Betrayal |
| 45464 | Satan Triumphant | Satana likuyushchiy |
| 45465 | Queerama | Queerama |
45466 rows × 2 columns
Duomenyse yra du panašūs stulpeliai, kurie rodo filmo pavadinimą ir filmo pavadinimą originalo kalba. Analizei naudosime filmo anglišką pavadinimą, todėl perteklinį stulpelį galima ištrinti.
Panaikiname ir kitus stulpelius, kurių nenaudosime analizėje.
movies_2 = movies.drop(['adult', 'original_title', 'poster_path', 'video'], axis = 1)
movies_2.head(3)
| id | collection_id | belongs_to_collection | budget | genre_1 | genre_2 | genre_3 | genre_4 | overview | popularity | ... | production_countries_2 | release_date | revenue | runtime | spoken_languages | status | tagline | title | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 862 | 10194.0 | Toy Story Collection | 30000000 | Animation | Comedy | Family | NaN | Led by Woody, Andy's toys live happily in his ... | 21.946943 | ... | NaN | 10/30/1995 | 373554033.0 | 81.0 | en | Released | NaN | Toy Story | 7.7 | 5415.0 |
| 1 | 8844 | NaN | NaN | 65000000 | Adventure | Fantasy | Family | NaN | When siblings Judy and Peter discover an encha... | 17.015539 | ... | NaN | 12/15/1995 | 262797249.0 | 104.0 | en, fr | Released | Roll the dice and unleash the excitement! | Jumanji | 6.9 | 2413.0 |
| 2 | 15602 | 119050.0 | Grumpy Old Men Collection | 0 | Romance | Comedy | NaN | NaN | A family wedding reignites the ancient feud be... | 11.7129 | ... | NaN | 12/22/1995 | 0.0 | 101.0 | en | Released | Still Yelling. Still Fighting. Still Ready for... | Grumpier Old Men | 6.5 | 92.0 |
3 rows × 23 columns
"Release date" stulpelio tipą pakeičiame į "Datetime" tipą.
movies_2['release_date'] = pd.to_datetime(movies_2['release_date'], format = '%m/%d/%Y', errors = 'coerce')
pd.to_datetime(movies_2['release_date'], format = '%Y-%m-%d', errors = 'coerce')
movies_2['release_date'] = pd.to_datetime(movies_2['release_date'], format = '%m/%d/%Y', errors = 'coerce').fillna(pd.to_datetime(movies_2['release_date'], format = '%Y-%m-%d', errors = 'coerce'))
movies_2['budget'].value_counts()
budget
0 36573
5000000 286
10000000 259
20000000 243
2000000 242
...
2489400 1
2494400 1
25 1
250050 1
998000 1
Length: 1226, dtype: int64
Matome, jog 36 573 filmų neturi duomenų apie biudžetą (reikšmė lygi 0). Kad būtų paprasčiau atlikti tolimesnę biudžeto analizę ir ji būtų tikslesnė, 0 pakeisime Nan reikšme, prieš tai biudžeto stulpelio reikšmes pavertę į 'numeric'.
movies_2['budget'] = pd.to_numeric(movies_2['budget'], errors='coerce')# If ‘coerce’, then invalid parsing will be set as NaN
movies_2['budget'] = movies_2['budget'].replace(0, np.nan)
movies_2['budget'].value_counts(dropna = False)
NaN 36576
5000000.0 286
10000000.0 259
20000000.0 243
2000000.0 242
...
2115000.0 1
1590000.0 1
1978000.0 1
1182273.0 1
2135161.0 1
Name: budget, Length: 1223, dtype: int64
Panašiai sutvarkysime ir 'revenue' stulpelio duomenis (0 reikšmes pakeisime į Nan, kad toliau galėtume atlikti skaitinę analizę).
movies_2['revenue'].value_counts()
0.0 38052
12000000.0 20
11000000.0 19
10000000.0 19
2000000.0 18
...
31554855.0 1
9627492.0 1
30822861.0 1
13960203.0 1
38702310.0 1
Name: revenue, Length: 6863, dtype: int64
movies_2['revenue'] = movies_2['revenue'].replace(0, np.nan)
movies_2['revenue'].astype(float)
movies_2['revenue'].value_counts(dropna = False)
NaN 38058
12000000.0 20
11000000.0 19
10000000.0 19
2000000.0 18
...
31554855.0 1
9627492.0 1
30822861.0 1
13960203.0 1
38702310.0 1
Name: revenue, Length: 6863, dtype: int64
Analizę pradėsime nuo rodiklio skaičiavimo, kuris parodys, ar filmas buvo pelningas, ar ne. Reikšmės, didesnės už 1, rodo, jog filmas uždirbo pelną. Kuo rodiklis aukštesnis, tuo didesnis buvo filmo pelnas.
movies_2['return'] = movies_2['revenue'] / movies_2['budget']
movies_2['return'] = movies_2[['return']].round(decimals = 2)
movies_2['return'] = movies_2['return'].replace(0, np.nan)
movies_2[movies_2['return'].isnull()].shape
(40147, 24)
40 147 filmų duomenų apie pelningumą neturi, tačiau atliksime analizę su likusiais 5 319 filmų.
movies_2[['title', 'return']].dropna(subset = ['return'])
| title | return | |
|---|---|---|
| 0 | Toy Story | 12.45 |
| 1 | Jumanji | 4.04 |
| 3 | Waiting to Exhale | 5.09 |
| 5 | Heat | 3.12 |
| 8 | Sudden Death | 1.84 |
| ... | ... | ... |
| 45167 | Wind River | 16.80 |
| 45250 | Sivaji: The Boss | 1.58 |
| 45409 | Savages | 1.66 |
| 45412 | Pro Lyuboff | 0.63 |
| 45422 | Antidur | 0.28 |
5319 rows × 2 columns
Pirmiausiai apžvelgsime biudžeto stulpelio statistinius duomenis.
movies_2['budget'].astype(float)
movies_2['budget'].describe()
count 8.890000e+03 mean 2.160428e+07 std 3.431063e+07 min 1.000000e+00 25% 2.000000e+06 50% 8.000000e+06 75% 2.500000e+07 max 3.800000e+08 Name: budget, dtype: float64
Vidutinis filmo biudžetas pagal mūsų duomenis yra 21.6 mln. USD, o mediana - tik 8 mln., todėl galime manyti, kad tokį skirtumą nulemia išskirtinai didelio biudžeto filmų reikšmės (matome, jog maksimali reikšmė siekia net 380 mln. USD).
movies_2[['title', 'budget', 'revenue', 'return']].dropna().sort_values('budget', ascending = False).head(10)
| title | budget | revenue | return | |
|---|---|---|---|---|
| 17124 | Pirates of the Caribbean: On Stranger Tides | 380000000.0 | 1.045714e+09 | 2.75 |
| 11827 | Pirates of the Caribbean: At World's End | 300000000.0 | 9.610000e+08 | 3.20 |
| 26558 | Avengers: Age of Ultron | 280000000.0 | 1.405404e+09 | 5.02 |
| 11067 | Superman Returns | 270000000.0 | 3.910812e+08 | 1.45 |
| 44842 | Transformers: The Last Knight | 260000000.0 | 6.049421e+08 | 2.33 |
| 16130 | Tangled | 260000000.0 | 5.917949e+08 | 2.28 |
| 18685 | John Carter | 260000000.0 | 2.841391e+08 | 1.09 |
| 11780 | Spider-Man 3 | 258000000.0 | 8.908716e+08 | 3.45 |
| 21175 | The Lone Ranger | 255000000.0 | 8.928991e+07 | 0.35 |
| 31072 | Batman v Superman: Dawn of Justice | 250000000.0 | 8.732602e+08 | 3.49 |
Matome, jog brangiausias filmas buvo "Pirates of the Caribbean" (šio filmo kita dalis užima ir antrąją vietą). Top 3 užbaigia "Avengers". Kaip buvo minėta anksčiau, "return" rodiklis, didesnis už 1, rodo, jog filmas buvo pelningas. Galime pastebėti, jog visi filmai, išskyrus vieną ("The Lone Ranger"), gavo pelną.
movies_2['revenue'].describe()
count 7.408000e+03 mean 6.878739e+07 std 1.464203e+08 min 1.000000e+00 25% 2.400000e+06 50% 1.682272e+07 75% 6.722707e+07 max 2.787965e+09 Name: revenue, dtype: float64
movies_2[['title', 'budget', 'revenue', 'return']].dropna().sort_values('revenue', ascending = False).head(10)
| title | budget | revenue | return | |
|---|---|---|---|---|
| 14551 | Avatar | 237000000.0 | 2.787965e+09 | 11.76 |
| 26555 | Star Wars: The Force Awakens | 245000000.0 | 2.068224e+09 | 8.44 |
| 1639 | Titanic | 200000000.0 | 1.845034e+09 | 9.23 |
| 17818 | The Avengers | 220000000.0 | 1.519558e+09 | 6.91 |
| 25084 | Jurassic World | 150000000.0 | 1.513529e+09 | 10.09 |
| 28830 | Furious 7 | 190000000.0 | 1.506249e+09 | 7.93 |
| 26558 | Avengers: Age of Ultron | 280000000.0 | 1.405404e+09 | 5.02 |
| 17437 | Harry Potter and the Deathly Hallows: Part 2 | 125000000.0 | 1.342000e+09 | 10.74 |
| 22110 | Frozen | 150000000.0 | 1.274219e+09 | 8.49 |
| 42222 | Beauty and the Beast | 160000000.0 | 1.262886e+09 | 7.89 |
Matome, jog daugiausiai pajamų gavo filmas "Avatar" (2.8 mlrd. USD). Antroje ir trečioje vietoje atitinkamai "Star Wars" ir "Titanic". Galima pastebėti, jog visų filmų "return" rodiklis yra didesnis už 1, tai reiškia, jog visi filmai buvo pelningi. Tačiau matome, jog tarp TOP 3 daugiausia pajamų gavusių filmų nėra nei vieno filmo iš daugiausiai kainavusių filmų TOP 3. Tai rodo, kad nebūtinai didžiausią biudžetą turėję filmai buvo sėkmingiausi ir uždirbo daugiausiai.
1-ąją hipotezę galime atmesti, nes didžiausio biudžeto filmas "Pirates of the Caribbean: On Stranger Tides" nesugeneravo daugiausiai pajamų - tai padarė filmas "Avatar".
movies_2['runtime'] = movies_2['runtime'].replace(0, np.nan)
movies_2['runtime'].describe()
count 43645.000000 mean 97.488303 std 34.644505 min 1.000000 25% 86.000000 50% 95.000000 75% 107.000000 max 1256.000000 Name: runtime, dtype: float64
Matome, jog vidutinis filmo ilgis yra 97 minutės. Mediana beveik sutampa su vidurkiu, tai reiškia, jog trukmė pasiskirsčiusi gana tolygiai. Maksimali trukmė yra net 1256 min., todėl galime daryti išvadą, jog tai tikriausiai ne filmas, o mini serialas.
movies_2[movies_2['runtime'] < 300][['title', 'runtime', 'release_date']].dropna(subset = ['runtime']).sort_values('runtime', ascending = False).head(10)
| title | runtime | release_date | |
|---|---|---|---|
| 42034 | The Phantom | 299.0 | 1943-12-24 |
| 3409 | Smoking / No Smoking | 298.0 | 1993-12-15 |
| 24938 | Long Way Round | 294.0 | 2004-10-03 |
| 7473 | Frank Herbert's Dune | 292.0 | 2000-12-03 |
| 44097 | The Private Life of Plants | 292.0 | 1995-01-01 |
| 22991 | Cranford | 291.0 | 2007-11-18 |
| 34263 | Naval Cadets, Charge! | 290.0 | 1987-06-06 |
| 32777 | 12 Chairs | 290.0 | 1976-12-31 |
| 18407 | The Nazis - A Warning From History | 289.0 | 1997-09-10 |
| 20999 | As I Was Moving Ahead Occasionally I Saw Brief... | 288.0 | 2000-07-19 |
Nustatant TOP 10 ilgiausių filmų, buvo padaryta prielaida, jog filmo trukmė neviršija 300 min. Didesnės reikšmės šiuo konkrečiu atveju bus traktuojamos kaip mini serialai.
movies_2[['title', 'runtime', 'release_date']].sort_values('runtime').head(10)
| title | runtime | release_date | |
|---|---|---|---|
| 35146 | La Vague | 1.0 | NaT |
| 36577 | Champs de Mars | 1.0 | 1900-08-21 |
| 36576 | Palace of Electricity | 1.0 | 1900-01-01 |
| 44965 | Luis Martinetti, Contortionist | 1.0 | NaT |
| 42357 | A Gathering of Cats | 1.0 | 2007-01-01 |
| 36575 | Eiffel Tower from Trocadero Palace | 1.0 | 1900-08-21 |
| 36574 | Panorama of Eiffel Tower | 1.0 | 1900-01-01 |
| 44714 | The Infernal Caldron | 1.0 | 1903-10-17 |
| 19244 | The Kiss | 1.0 | NaT |
| 44646 | The Vanishing Lady | 1.0 | NaT |
Matome, jog visi šie filmai truko tik po 1 minutę! Ir beveik visi jie buvo sukurti XIX a. pab. - XX a. pr., kuomet filmų istorija tik prasidėjo.
movies_2['vote_count'] = movies_2['vote_count'].replace(0, np.nan)
movies_2[['title', 'vote_count', 'vote_average', 'release_date']].sort_values('vote_count', ascending = False).head(10)
| title | vote_count | vote_average | release_date | |
|---|---|---|---|---|
| 15480 | Inception | 14075.0 | 8.1 | 2010-07-14 |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 2008-07-16 |
| 14551 | Avatar | 12114.0 | 7.2 | 2009-12-10 |
| 17818 | The Avengers | 12000.0 | 7.4 | 2012-04-25 |
| 26564 | Deadpool | 11444.0 | 7.4 | 2016-02-09 |
| 22879 | Interstellar | 11187.0 | 8.1 | 2014-11-05 |
| 20051 | Django Unchained | 10297.0 | 7.8 | 2012-12-25 |
| 23753 | Guardians of the Galaxy | 10014.0 | 7.9 | 2014-07-30 |
| 2843 | Fight Club | 9678.0 | 8.3 | 1999-10-15 |
| 18244 | The Hunger Games | 9634.0 | 6.9 | 2012-03-12 |
movies_2['vote_average'] = movies_2['vote_average'].replace(0, np.nan)
movies_2[movies_2['vote_count']> 3000][['title', 'vote_average', 'vote_count', 'release_date']].sort_values(['vote_average','vote_count'], ascending = False).nlargest(10, 'vote_average')
| title | vote_average | vote_count | release_date | |
|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8.5 | 8358.0 | 1994-09-23 |
| 834 | The Godfather | 8.5 | 6024.0 | 1972-03-14 |
| 12481 | The Dark Knight | 8.3 | 12269.0 | 2008-07-16 |
| 2843 | Fight Club | 8.3 | 9678.0 | 1999-10-15 |
| 292 | Pulp Fiction | 8.3 | 8670.0 | 1994-09-10 |
| 522 | Schindler's List | 8.3 | 4436.0 | 1993-11-29 |
| 23673 | Whiplash | 8.3 | 4376.0 | 2014-10-10 |
| 5481 | Spirited Away | 8.3 | 3968.0 | 2001-07-20 |
| 2211 | Life Is Beautiful | 8.3 | 3643.0 | 1997-12-20 |
| 1178 | The Godfather: Part II | 8.3 | 3418.0 | 1974-12-20 |
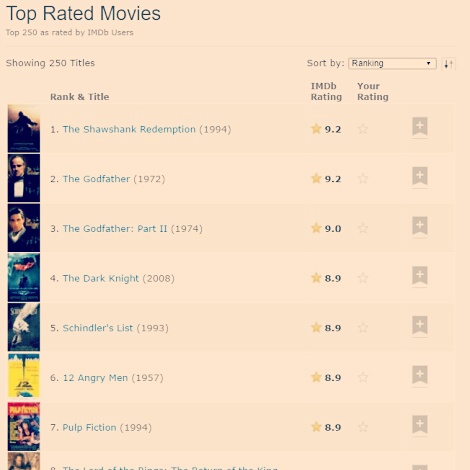
Filtruojant TOP 10 aukščiausius įvertinimus turinčių filmų, buvo pridėta papildoma sąlyga, jog filmas turi turėti bent 3000 balsų. Tokiu būdu gautas rezultatas labiau atitiks realią situaciją.
Galime patvirtinti 2-ąją hipotezę, jog daugiausiai balų surinkęs filmas sutampa su IMDB reitingo 1-ąja vieta ("The Shawshank Redemption").
movies_2['title'] = movies_2['title'].astype(str)
stop = stopwords.words('english')
movies_2['title_without_stop'] = pd.Series(movies_2['title'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)])))
pd.Series(' '.join(movies_2['title_without_stop']).lower().split()).value_counts()[:10]
the 10082 a 1235 man 639 love 635 my 532 i 477 & 455 story 393 night 382 life 377 dtype: int64
Pagal atliktą analizę matome, jog populiariausias žodis filmo pavadinime yra "man", bet "love" nuo jo atsilieka labai nedaug. Tačiau 3-ąją hipotezę visgi turime atmesti.

movies_2['tagline'] = movies_2['tagline'].astype(str)
stop = stopwords.words('english')
movies_2['tagline_without_stop'] = pd.Series(movies_2['tagline'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)])))
pd.Series(' '.join(movies_2['tagline_without_stop']).lower().split()).value_counts()[:10]
nan 25054 the 3883 a 2344 one 1242 love 855 story 750 never 639 you 618 they 591 in 575 dtype: int64
Matome, jog žodžiai "love" ir "story" yra vieni populiariausių tiek filmų pavadinimuose, tiek jų trumpuose apibūdinimuose. Galime daryti išvadą, jog meilės ir romantikos tema yra dominuojanti filmų industrijoje.
movies_2['spoken_languages'] = movies_2['spoken_languages'].astype(str)
movies_2['spoken_languages'] = movies_2['spoken_languages'].replace('0', np.nan)
def kableliai(txt):
return txt.replace(',', '')
Top_languages = pd.Series(' '.join(movies_2['spoken_languages'].apply(kableliai)).lower().split()).value_counts()[:15]
Top_languages
en 28743 fr 4196 nan 3836 de 2625 es 2411 it 2367 ja 1757 ru 1563 zh 788 hi 707 pt 590 sv 558 ko 541 pl 523 cn 472 dtype: int64
Matome, jog populiariausios filmų kalbos yra anglų, prancūzų bei vokiečių.
Top_10 = np.array(pd.Series(' '.join(movies_2['spoken_languages'].apply(kableliai)).lower().split()).value_counts()[:10])
lan_labels = ['English', 'French','Nan','German', 'Spanish', 'Italian', 'Japanese', 'Russian', 'Mandarin', 'Hindi']
plt.pie(Top_10, labels = lan_labels, autopct='%1.0f%%', shadow = True, explode = [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1], radius = 1.4)
plt.show()

def skliaustai (txt):
return txt.replace(']', '')
movies_2['genre_1'] = movies_2['genre_1'].astype(str)
movies_2['genre_2'] = movies_2['genre_2'].astype(str)
movies_2['genre_3'] = movies_2['genre_3'].astype(str)
movies_2['genre_4'] = movies_2['genre_4'].astype(str)
movies_2['genre_1'] = movies_2['genre_1'].apply(skliaustai)
movies_2['genre_1'].value_counts()
Drama 11966 Comedy 8820 Action 4489 Documentary 3415 Horror 2619 nan 2445 Crime 1685 Thriller 1665 Adventure 1514 Romance 1191 Animation 1124 Fantasy 704 Science Fiction 647 Mystery 554 Family 524 Music 487 Western 451 TV Movie 390 War 379 History 279 Foreign 118 Name: genre_1, dtype: int64
Populiariausias filmų žanras mūsų duomenų bazėje yra "Drama". Antroje vietoje yra komedijos, o trečioje - veiksmo filmai, kurių yra jau dvigubai mažiau nei antroje vietoje esančių veiksmo filmų. Taigi, galime patvirtinti ir ketvirtąją hipotezę, jog populiariausias filmų žanras yra drama.
len(np.unique(movies_2[['genre_1', 'genre_2', 'genre_3', 'genre_4']]))
21
Mūsų duomenų bazėje yra iš viso 21 žanro rūšis.
genre_df = pd.DataFrame(movies_2['genre_1'].value_counts()).reset_index()
genre_df.columns = ['genre', 'movie_count']
genre_df.head()
| genre | movie_count | |
|---|---|---|
| 0 | Drama | 11966 |
| 1 | Comedy | 8820 |
| 2 | Action | 4489 |
| 3 | Documentary | 3415 |
| 4 | Horror | 2619 |
plt.figure(figsize=(20,6))
sns.set_theme(style="whitegrid")
sns.barplot(x='genre', y='movie_count', data = genre_df)
plt.show()

movies_2.groupby(movies_2['release_date'].dt.month)['release_date'].count().sort_values(ascending = False)
release_date 1.0 5876 9.0 4834 10.0 4610 12.0 3779 11.0 3653 3.0 3549 4.0 3450 8.0 3390 5.0 3332 6.0 3151 2.0 3032 7.0 2639 Name: release_date, dtype: int64
Pagal atliktą analizę matome, jog dažniausiai filmai išleidžiami sausio mėnesį. Nedaug atsilieka ir rugsėjis. Šie mėnesiai kino industrijoje dar kitaip vadinami "dump months" - sausį Kalėdų periodas jau būna praėjęs, o rugsėjį visi mokiniai grįžta į mokyklas ir labai sumažėja paklausa, todėl šiais mėnesiai kino teatrai dažniausiai rodo filmus, kuriems nėra prognozojama didelė sėkmė.
Hipotezių patvirtinimas/atmetimas: